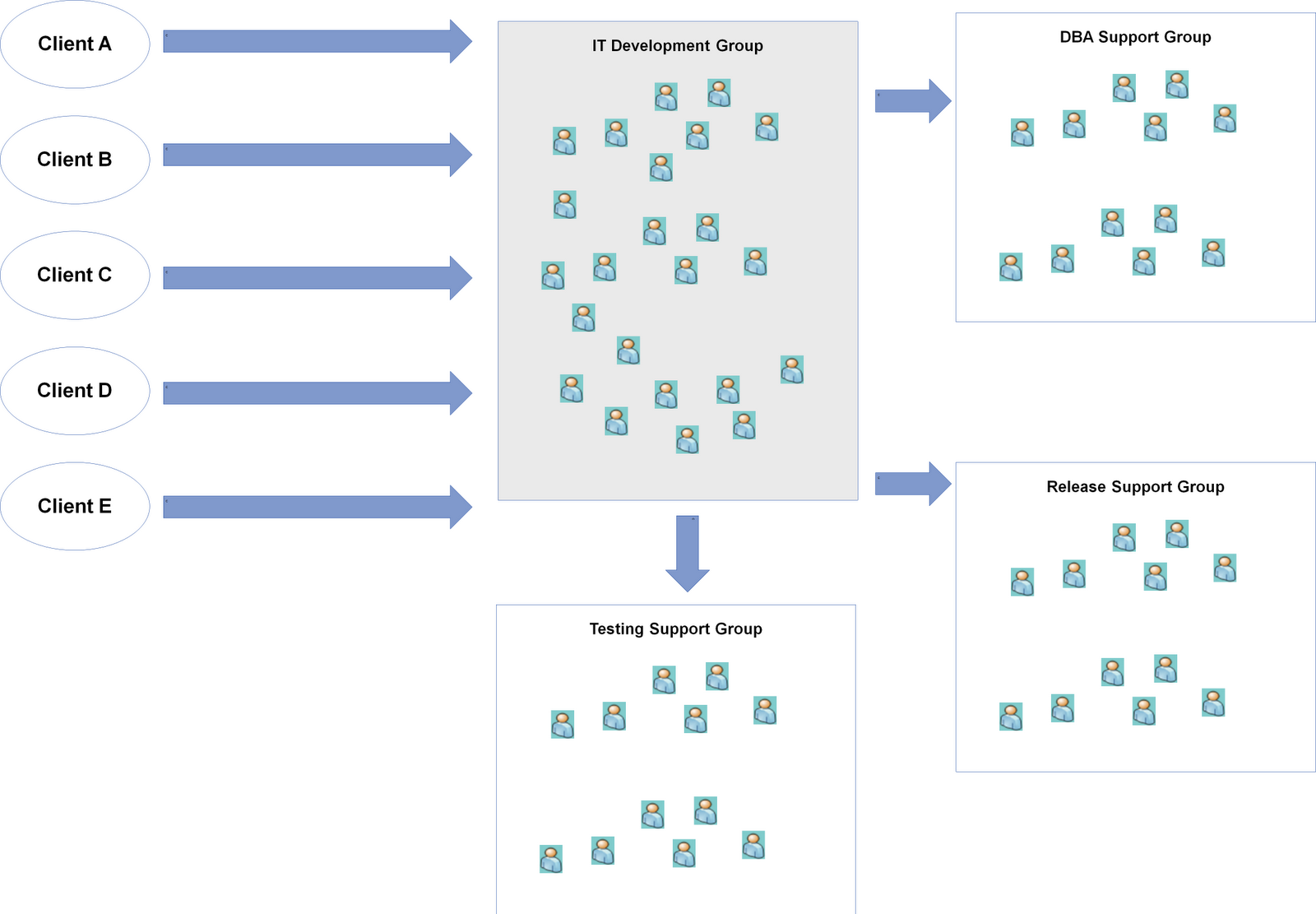
Step 1) Identify the various upstream and downstream groups with a special emphasis on external "support groups" for the group adopting Kanban
In our scenario, we were helping an IT Development Group adopt Kanban. To start, we need to first identify who are upstream parties that give us work, in this it's the clients/business themselves that have a PM/BA function and there are 5 of them. There is one downstream group, the Release Support Group that is responsible for packaging, and pushing code into staging and production. The final group to look at is other support groups which tends to be a key consideration in enterprise settings since most IT organizations have moved towards functional consolidation. For this particular group, they rely on a DBA Support Group, and a Testing Support Group in order for them to complete their work and pass it to the release group.
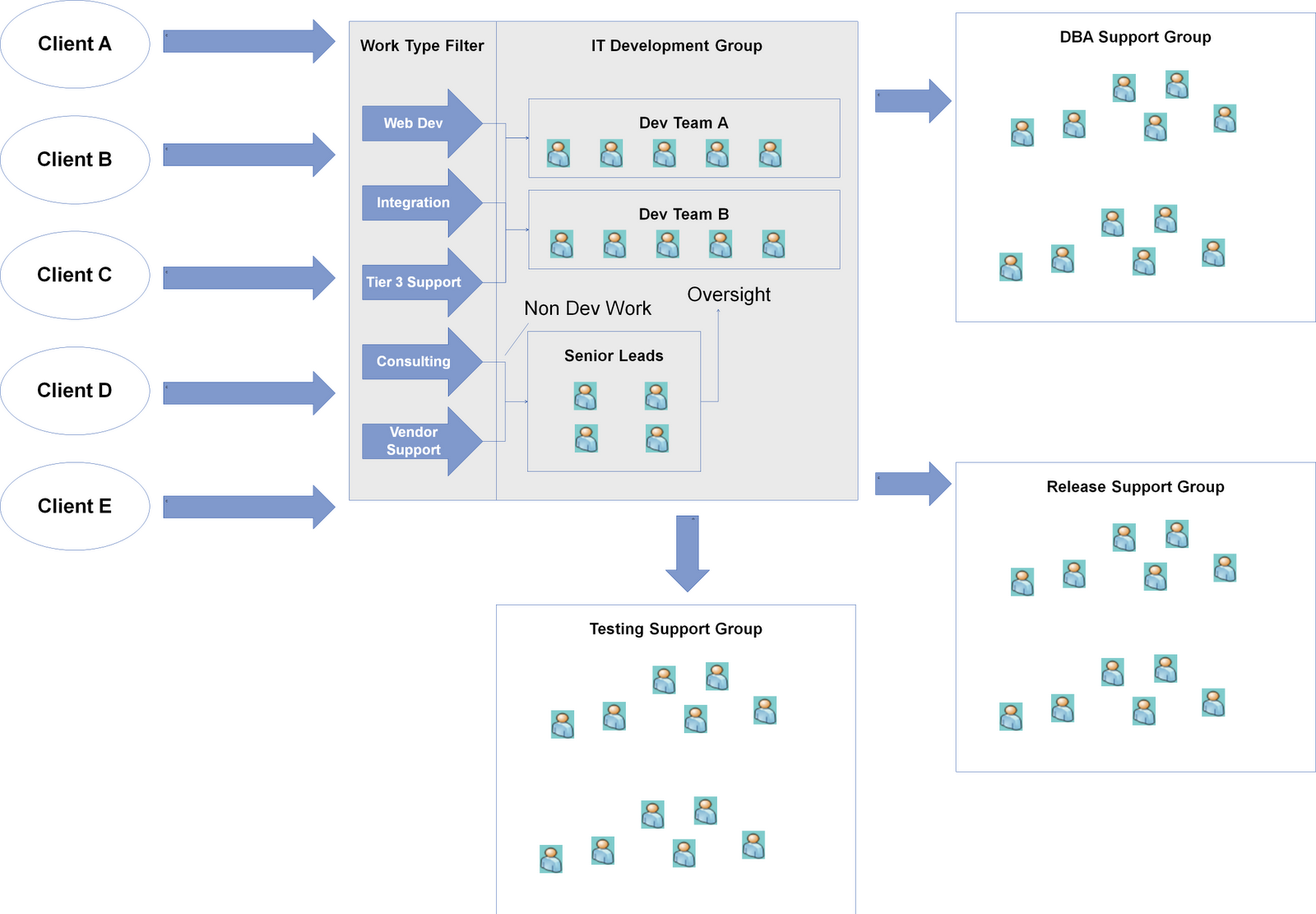
Step 2) Identify the work types that come in from the upstream provider and work with the IT Development Group to agree on a set of standard work types to setup a "Work Type Filter"
One of the lessons we learned during our work with a number of teams is the importance to treat the work type analysis as a capability and not a one-time event. Work type requests evolve over time and the team needs to develop the capability to conduct this activity and evolve a standard set of work types. I find thinking of this as implementing a Work Type Filter for the team helpful so they understand it's a capability and mechanism they need to operationalize. Work type analysis tends to be always be an interesting conversation with the IT Development Group in enterprise IT settings since the development teams will have other "responsibilities" besides writing code. They are often called upon by the client or other groups to provide two types of non-development services, Consulting, and Vendor Support / Management. Since functional consolidation tends to exist in most IT organizations I have seen, some type of centralized PM/BA function is often responsible for gathering requirements and providing estimates and plans. These groups lack the technical knowledge to complete these activities and as a result seek out the development groups for help. The second type of non-development request is often Vendor Support / Management. Business demand for solutions often tends to be non-stable and peaks near the end of the annual budgeting cycle as they feel the pressure to spend their budget which causes demand to exceed internal development capacity which in turn leads to the organization running to scale up with external vendors to take on the extra work. This will generate some work for the development group as the PMs will often ask the group to provide technical oversight or support to guide design, coding and help with code integration and promotions. I find it extremely helpful to separate these non-development requests from development work types since they often cause noise in the system and impact capacity in a different way. Turning back to our real-world example, here's what we ended up with:
Step 3) Map out the internal value stream, and identify where hand-offs and coordination with support groups occur in the process
Now that we understand the boundaries of our Kanban system we can start digging into the internal workings and understand how everything connects. Value stream mapping is often a useful tool for this, but I find keeping it simple works best. The important part of this step is to explicitly map out where the "interface" to the team is with other support groups and understand what information / value / artifacts is traded (i.e. what the interface contract should look like).

Step 4) Visualize all work in terms of the standard work types, let the system run to understand throughput and then set WIP limits with an emphasis on the input queue and external support group columns
At the end of step 3, we should have a kanban board and we can start onboarding all the work the IT Development Group is currently working on in terms of the standard work types we defined for the Work Type Filter. I find many teams struggle with setting WIP limits right away, and they need to use the Kanban system for 2-4 weeks before they have the right comfort level to have this discussion. At that point, the throughput metric should be tracked as this will provide a helpful frame of reference to set the initial guesstimate for the WIP limits. The key columns I focus on with the group is the input queue and external hand-off columns. The rationale behind focusing on these columns is they are the interfaces to the outside world and we want to start setting some expectations and commitments around these as the IT Development Group needs their help to deliver work. The input queue keeps them fed and the hand-off columns keep them running. I often leverage the throughput metric to orient the team around a WIP limit for the input queue based on the simple guideline of only take in what you can finish.

Step 5) Expose the queues to the clients and help setup and operationalize a prioritization framework as a Prioritization Filter
At this point, we expose the queues to the clients and start pushing prioritization of work to the customer. We also find in enterprise IT settings, providing only a next/this month queue is insufficient for their planning process. As a result we often provide a prioritized backlog mechanism with two replenishment cadences, an annual/quarterly one for strategic/budget planning a monthly one for just-in-time decisions. This is where we often see the most churn and is typically the most challenging part of the Kanban process. Many IT organizations are great at prioritizing within one group, but across organizational groups is a struggle despite attempts at elaborate and agonizing prioritization committees/boards. To help with this problem, the Kanban system arms us with two pieces of information, a common unit of currency (the standard work types) and delivery throughput. Leveraging these two pieces of information, we recommend working with the clients to analyze all their known demand, break it down using the Work Type Filter into our standard work types, and then calculating the gap between demand vs capacity in terms of throughput. Once the gap is known, there are two options, scaling up with more external vendors or prioritizing the work. In this scenario, scaling up was not an option due to the tight deadlines and the ramp up time needed to onboard new resources so we had to go with the prioritization option. To help with the prioritization problem, we recommend holding a workshop to align the requests with strategic priorities for the organization and then applying a FIFO policy to these requests while considering true fixed date items. This provides a workable interim solution as it forces the clients to focus on today with FIFO. The goal is to get to a set of demand channels based on what's ready to go now or soon and set % allocation against these channels. We then provide the client an opportunity to adjust the % allocation during the monthly replenishment meetings.

After this step, you should have a fully operational Kanban system. Now the hard but fun part remains which is evolving it and optimizing it for performance.

